「&.(アンド ドット)」と「try」の違い
【結論】
・「&.(アンド ドット)」と「try」は
どちらもレシーバーがnilの時に、
「NoMethodError」ではなく、
「nil」を返してくれる機能
・「&.(アンド ドット)」は、そもそもメソッドが
定義されていない場合には、エラーを返す。
・「try」は、メソッドが定義されていない場合でも、
エラーにはならずnilを返す。
【目次】
【本題】
nilClassによるNoMethodErrorを防ぐ手段
"1 2 3".split => ["1", "2", "3"] nil.split => NoMethodError (undefined method `split' for nil:NilClass)
上記の様に、NilClassに定義されていないメソッドを
nilに対して使用した場合、NoMethodErrorのエラーが返ります。
しかしそういったエラーを出したく無いケースも存在します。
そういった場合に利用できるのが、
「&.(アンド ドット)」と「try」です。
「&.(アンド ドット)」について
nil&.split => nil
「try」について
ActiveSupportで提供されているメソッドです。
nil.try(:split) => nil
それぞれの違い
それぞれの違いは、メソッドが呼び出し可能かを判断して処理を返す点です。
「try」はメソッドが呼び出し可能かまで判定するので、
メソッドが定義されていない場合でも、 エラーにはならずnilを返す。
「&.(アンド ドット)」は、レシーバがnilかの判定しかしないので、
メソッドが定義されていない場合には、エラーを返します。
nil.try(:undefined) => nil nil&.undefined => NoMethodError: undefined method
WYSIWYGエディタについて
【結論】
・WYSIWYGエディタとは、アプリケーションに実装する事で、
ユーザーが入力したテキストの文字サイズなどを
感覚的に調整して投稿する事が出来る機能
・Rails 6では「Action Text」という
WYSIWYGエディタが実装される
・ActionTextでは、WYSIWYGエディタに「Trix」
画像アップローダに「ActiveStorage」を利用している
【目次】
【本題】
WYSIWYGエディタとは
WYSIWYGエディタとは、アプリケーションに組み込む事で、
ユーザーが入力したテキストの文字サイズなどを
自身の手で直感的に変更して、投稿する事が出来る機能です。
「What You See Is What You Get」の略
→Google翻訳「あなたが見たもの、それがあなたの手に入れたものだ!」
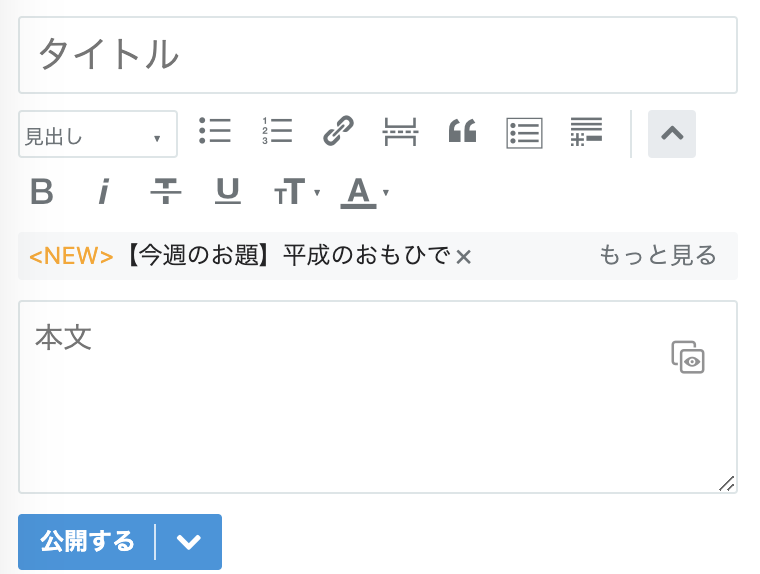
はてなブログだと、下記の様な投稿フォームがそれに当たります。
Rails 6では「Action Text」
Rails 6から「Action Text」という機能が実装されます。
これにより、Rails単体でWYSIWYGエディタを実装出来ます。
「Action Text」で利用される技術
ActionTextでは、WYSIWYGエディタに「Trix」
画像アップローダに「ActiveStorage」を利用されています。
・Trix
Railsを生み出したBasecampが作成したWYSIWYGエディタです。
日本語表示はありませんが、シンプルなので、直感的に操作が出来ます。
・ActiveStorage
Rails5.2から実装されている機能で、
画像などのファイルアップロードをサポートしてくれます。
「render」「redirect_to」の違い
【結論】
・「render」「redirect_to」共に
ページを更新させる為のメソッド
・「render」は指定したviewファイルを呼び出し、
「redirect_to」は指定したパスにアクセスする
・エラーで元の画面に戻したい場合は「render」
データを更新してページを表示させたい場合は「redirect_to」
という使い分けが最適
【目次】
【本題】
「render」「redirect_to」について
Railsでページを更新させる処理を行う事が可能なメソッドとして、
「render」「redirect_to」が用意されています。
一見すると同じ挙動の様に見えますが、
それぞれに適した利用シーンがあるので、
仕様の違いと共に、解説します。
「render」について
「render」は、指定したviewファイルに
アクセスする為のメソッドです。
下記の様にコントローラーで記述すると
コントローラーに属するディレクトリ配下の
veiwファイル(new)を呼び出します。
なお、インスタンス変数は更新されず、
以前に取得した物をそのまま流用します。
render :new
また、下記の様にveiwファイルに記述する事で、
指定したviewファイルを呼び出す事も可能です。
<%= render 'form' %>
「redirect_to」について
「redirect_to」は、指定したパスに
アクセスする為のメソッドです。
直接リンクをクリックした時などと同じ挙動になるので、
インスタンス変数が更新されます。
下記の様に記述する事で、
名前付きルートのパスへ移動します。
redirect_to users_path
それぞれの使い分け
上記で記述した通り、それぞれの大きな違いは
インスタンス変数が更新されるか?否か?です。
なので、エラーなどで処理が正常に完了せず、
元の画面に戻したいだけの時や、
部分テンプレートを呼び出したい場合などには、
「render」を利用します。
一方で、処理が正常に完了した後に、
違うページに遷移させたりなど、データの更新が必要な場合は、
「redirect_to」を用いるのが最適な使い分けになります。
「pluck」と「map」の違いについて
【結論】
・任意のカラムの配列を取得する方法として
「pluck」と「map」の二つのメソッドが存在する
・「map」はRubyのメソッドで、
要素の数だけブロックを実行し、戻り値を集めた配列を返す
「pluck」はRailsのメソッドで
指定任意のカラムの配列を取得する。
・DBからデータを直接取得する場合は「pluck」
インスタンスから取得する場合は「map」の方が
処理速度が早くなる傾向にある
【目次】
【本題】
特定カラムのデータだけを一括で取得する方法
テーブルの特定のカラムのデータだけを一括して
取得したい場合があります。
そういった場合に使用出来るのが、
「pluck」と「map」というメソッドです。
「map」について
「map」はRubyに組み込まれているメソッドです。
要素の数だけブロックを実行して、
ブロックの戻り値を集めた配列を返します
num = [1,2,3,4,5] num.map {|i| i * 2 } => [2, 4, 6, 8, 10]
「pluck」について
「pluck」はRailsに組み込まれているメソッドで、
Rubyだけでは使用できません。
モデル(インスタンス)から
指定したカラムのデータだけを一括で取得できます。
model.pluck(column)
どのように使い分けるべきか?
基本的に「map」はメモリ内で処理を行う際のメモリ消費がネックとなり、
「pluck」の方が処理速度は早いようですが、一つ欠点があります。
それは、「pluck」では毎回SQLが発行されるという点です。
これは、既にインスタンス化されたオブジェクトから
値を取得する時にもSQLが発行されてしまいます。
一方、「map」であれば、メモリ内で処理を行うだけで済みます。
なので、DBから値を取得する場合には「pluck」、
既にインスタンス化したオブジェクトから値を取得する場合は「map」、
という使い分けが最も最適のようにです。
配列の重複した要素を取得するメソッドが無い問題とその対処方法
【結論】
・Ruby(Rails)では、
重複した値を除去するメソッドは用意されているが、
重複している値を取得するメソッドは存在しない
・重複した値を取得する場合は、
複数のメソッドを組み合わせて
処理を行う必要がある
・「array.group_by{|i| i}.reject{|k,v| v.one?}.keys」
【目次】
【本題】
CSVからユーザー情報を登録する機能を実装した時の話
仕事でCSVからユーザーの情報を
一括で登録出来る機能の実装をしたのですが、
仕様にある問題がありました。
それは、CSVファイル内で、メールアドレスなどの
ユニークであるべき値が重複していた場合に発生します。
モデルにバリデーションは設定していたので、
同じ値のレコードが複数生成される事はありませんが、
一番最初に読み込まれたデータは登録されてしまうという仕様になっていました。
重複している以上、そのデータが誤りである可能性も考えられ流ので、
重複しているメールアドレスを持っているデータは、
一切登録されない様に、あらかじめ除外するコードを書こうとしました。
Ruby(Rails)には、重複した値を除去するメソッドが無い
「Ruby 重複」などで検索してみると、下記の様なメソッドがヒットしました。
uniq uniq!
これらは、配列に対して利用できるメソッドで、
配列内の重複している要素を削除した新しい配列を返します。
「uniq!」はレシーバー自体の値を変更します。
mail = ["mail1", "mail1", "mail1", "mail1", "mail2", "mail3", "mail4", "mail5"] mail.uniq => ["mail1", "mail2", "mail3", "mail4", "mail5”] mail => ["mail1", "mail1", "mail1", "mail1", "mail2", "mail3", "mail4", "mail5"] mail.uniq! => ["mail1", "mail2", "mail3", "mail4", "mail5”] mail => ["mail1", "mail2", "mail3", "mail4", "mail5"]
しかし、これは重複している要素を除去するだけで、
重複している要素の特定には使えません。
他にも色々探してみましたが、
重複している要素を特定するメソッドは見当たりませんでした。
メソッドを組み合わせて、重複を特定する
そんな時に、下記のサイトを発見しました。
https://doruby.jp/users/pe/entries/ruby%E3%81%A7%E9%85%8D%E5%88%97%E3%81%8B%E3%82%89%E9%87%8D%E8%A4%87%E3%81%99%E3%82%8B%E5%80%A4%E3%82%92%E6%8A%BD%E5%87%BA%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95%E3%82%92%E6%8E%A2%E3%81%97%E3%81%9F%E9%9A%9B%E3%81%AB%E8%A6%8B%E3%81%A4%E3%81%91%E3%81%9Fgroup_by%E3%83%A1%E3%82%BD%E3%83%83%E3%83%89%E3%81%8C%E4%BE%BF%E5%88%A9%E3%81%A0%E3%81%A3%E3%81%9Fdoruby.jp
これによると「group_by」「reject」「one?」「keys」のメソッドを
組み合わせて使用することで、直接重複している要素を取得できる様です。
それぞれのメソッドの仕様は下記の通りです。
「group_by」
ブロック引数に各要素を入れて、要素の数だけブロックを実行。
ブロックの返り値が同じ要素を下記の様に一つのハッシュにまとめて返す。
{ 返り値 => [要素, 要素, ...], ... }
mail = ["mail1", "mail1", "mail1", "mail1", "mail2", "mail3", "mail4", "mail5”] mail.group_by{|i| I} => {"mail1"=>["mail1", "mail1", "mail1", "mail1"], "mail2"=>["mail2"], "mail3"=>["mail3"], "mail4"=>["mail4"], "mail5"=>["mail5"]}
「reject」
ブロック引数に各要素を入れて、要素の数だけブロックを実行。
ブロックの返り値がfalseになった要素を集めた配列を返す。
mail = ["mail1", "mail1", "mail1", "mail1", "mail2", "mail3", "mail4", "mail5”] mail.reject {|i| i =="mail1" } => ["mail2", "mail3", "mail4", "mail5"]
「one?」
ブロック引数に各要素を入れて、要素の数だけブロックを実行。
返り値が1つだけtureだった場合にtrueを返し、それ以外はfalseを返す。
mail = ["mail1", "mail1", "mail1", "mail1", "mail2", "mail3", "mail4", "mail5”] mail.one? {|i| i =="mail1" } => false mail.one? {|i| i =="mail2" } => true
「keys」
ハッシュのキーを集めて配列にして返す。
user = { name: "ryoutaku", email: "mail@mail.com"}
=> {:name=>"ryoutaku", :email=>"mail@mail.com"}
user.keys
=> [:name, :email]
使ってみた
mail = ["mail1", "mail1", "mail1", "mail1", "mail2", "mail3", "mail4", "mail5”] mail.group_by{|i| i}.reject{|k,v| v.one?}.keys => ["mail1”]
きちんと、重複している値のみを取得できました!
一応、段階を追ってみていきます。
#重複している要素をグループにまとめる mail.group_by{|i| i} => {"mail1"=>["mail1", "mail1", "mail1", "mail1"], "mail2"=>["mail2"], "mail3"=>["mail3"], "mail4"=>["mail4"], "mail5"=>["mail5”]} #重複している要素のグループだけを取得 mail.group_by{|i| i}.reject{|k,v| v.one?} => {"mail1"=>["mail1", "mail1", "mail1", "mail1”]} #グループのキーを取得 mail.group_by{|i| i}.reject{|k,v| v.one?}.keys => ["mail1"]
これにより、重複している要素を取得する事が可能です。
file_fieldがある時、form_forやform_with はmultipart: trueが省略できる
【結論】
・multipartとは、form_forやform_withにおいて
マルチパートを指定するオプション
・マルチパートの指定は、
画像やCSVなどのファイルを読み込む際に必要で、
「multipart: true」と記述する
・Rails4以降のform_forやform_withでは、
フォーム内に関連付けられた「file_field」がある場合は、
自動的に「multipart: true」が適用されるので、
記述の省略が可能
【目次】
- form_forやform_withのオプションである「multipart」
- 「multipart: true」でマルチパートを認識可能に
- Rails4以降のform_forやform_withでは省略可能に
【本題】
form_forやform_withのオプションである「multipart」
form_forやform_withのオプションの中には、
「multipart」というものがあります。
これは、マルチパートを指定するオプションです。
マルチパートとは、画像やCSVなどのデータの種類を指します。
もし、このマルチパートの指定をしていないと、
ファイルを読み込んでも、ファイル名をただの文字列と認識してしまい、
ファイルを画像やCSVとして取り込む事が出来ません。
例えば、「image.jpeg」という画像ファイルを取り込んでも、
「image.jpeg」という文字列として認識されてしまいます。
「multipart: true」でマルチパートを認識可能に
画像を画像として、CSVをCSVとして取り込みたい場合は、
「multipart: true」と記述して、マルチパートの指定を行います。
こうする事で、ファイルそのものを正しく読み込む事が可能になります。
Rails4以降のform_forやform_withでは省略可能に
なお、この「multipart: true」ですが、
Rails4以降では省略可能になっています。
下記の様に、関連付けられた「file_field」が存在すれば、
自動的に「multipart: true」が適用されます。
<%= form_with url: import_csv_path, local: true do |f| %> <%= f.file_field :file %> <%= f.submit t('common.button.import') %> <% end %>
なお、下記の様に「file_field」が関連付けられていない場合(f.が無い)や、
そもそも「file_field」が無い場合には、「multipart: true」を設定する必要があります。
<%= form_with url: import_csv_path, local: true, multipart: true do %> <%= file_field_tag :file %> <%= submit_tag t('common.button.import') %> <% end %>
activerecord-importで、子レコードの同時インサートが出来ない問題
【結論】
・MySQLの場合、activerecord-importでは、
子レコードの同時インサートが出来ない。
(PosgreSQLでは可能)
・子レコードも同時にDBへ保存する場合は、
トランザクションをロックして、IDを紐付けた後に、
子レコードを別途バルクインサートする必要がある。
【目次】
- activerecord-importだと、子レコードが一緒にインサートされない
- activerecord-importで子モデルを同時にインサートする方法
- PosgreSQLのみ、同時インサートに対応
【本題】
activerecord-importだと、子レコードが一緒にインサートされない
前回、「activerecord-import」によるバルクインサートと、
「accepts_nested_attributes_for」による
子レコードの同時保存の方法を紹介しました。
実際の開発においては、
これらを組み合わせた機能を実装したい場面があります。
しかし、「activerecord-import」によるバルクインサートは、
子レコードの同時インサートに対応していません。
activerecord-importで子モデルを同時にインサートする方法
子レコードも同時にインサートしたい場合は
トランザクションをロックして、IDを紐づけたのちに、
子レコードを別にバルクインサートする必要があります。
下記が実装例です。
# トランザクションで、UserRoleのバルクインサートが失敗した場合、ロールバックする様にする User.transaction do # Userをバルクインサート User.import(users) # userにはUserのモデルオブジェクトが配列で格納されているので、eachで1件づつ取り出す users.each do|user| # モデルオブジェクトにはIDが割り振られていないので、DBから引っ張ってくる user = User.find_by(email: user.email) # IDを紐づけて、UserRoleのオブジェクトを生成 user_roles << user.user_roles.build(role_id: "1") end # Userをバルクインサート UserRole.import(user_roles) end
PosgreSQLのみ、同時インサートに対応
なお、PosgreSQLの場合は、「recursive: true」という
オプションを設定する事で、関連モデルも同時にインサートが可能です。
User.import(users), recursive: true
セキュリティグループとネットワークACL
【結論】
・セキュリティグループとネットワークACLは、
いずれもセキュリティを強化する為に
通信を制限したり許可する仕組み
・セキュリティグループは、送受信両方を、
ネットワークACLは送信か受信のどちらかを
任意で設定できる違いがある。
【目次】
【本題】
標的型攻撃に対抗する手段
インターネットのセキュリティを考える時、
真っ先に思い浮かぶのは「外部からのハッキング」ですが、
昨今は「標的型攻撃」と呼ばれる手法が増えています。
「標的型攻撃」とは、メールの添付ファイルを開いたり、
良く訪れるサイトに偽装された不正サイトにアクセスするなどして、
権限を乗っ取られて、不正操作をされるというものです。
この様な攻撃では、感染自体を防ぐのが最も重要ですが、
万が一感染したとしても、被害を最小限に食い止める対策も
同時に行う事が重要です。
そこで登場するのが「セキュリティグループ」と「ネットワークACL」です。
外部との通信を制限
「セキュリティグループ」と「ネットワークACL」は、
いずれもセキュリティを強化する為に、
外部との通信を制限するファイアウォールの様な役割を果たす仕組みです。
これらにより、万が一パソコンがウィルスに感染したとしても、
あらかじめ制限されたネットワークとしか通信出来なかったり、
特定のデータにしかアクセス出来なくなる為、被害を最小限に留める事が可能です。
セキュリティグループとネットワークACLの違い
それぞれの違いを説明する際、
セキュリティグループは「ステートフル」
ネットワークACLは「ステートレス」と言われます。
「ステートフル」は状態を保持したまま通信すること、
「ステートレス」は状態を保持しない通信を指します。
セキュリティグループを設定すると、
外部との通信の「送信」「受信」ともに制限を掛ける事が出来ます。
対して、ネットワークACLは、
「送信」「受信」のそれぞれに対して設定が必要になります。
細かな違いは、AWSの公式サイトでは以下の様な表で説明されています。

正直よく分からない部分が多いので、改めて勉強して解説したいと思います。
ちなみに、ACL(アクセスコントロールリスト)は、
ユーザーごとにアクセス可能なサーバや
アプリケーションを制限する仕組みです。
concernによるメソッドのMVC外部への切り出し
【結論】
・アプリケーションがある程度の規模になると
MVCに沿ってメソッドの切り分けを行っても、
コントローラーやモデルが肥大化して
拡張性・メンテナンス性に悪影響を及ぼす
・ ActiveSupport::Concernを用いれば
MVC外部にメソッドを切り出す事が可能になる
【目次】
【本題】
MVC外部に切り出しが必要な場面
Railsは、MVCアーキテクチャーに基づいて設計されており、
それぞれの役割に応じてコードを記述する場所を変えることで
拡張性とメンテナンス性を担保しています。
しかし、実際の業務レベルのアプリケーションは
様々な機能を実装する必要があり、MVCレベルの切り出しだけでは
コントローラやモデルが肥大化してしまい、
拡張性・メンテナンス性が落ちてしまいます。
そこで登場するのが、MVC外部へのメソッドの切り出しを
可能にするActiveSupport::Concernです。
ActiveSupport::Concernとは
ActiveSupport::Concernとは、MVC外部のconcernsというファイルに
メソッドを定義してMVCに呼び出すことで、
MVC側の記述量を減らし、またコードを共通化させることで
拡張性・メンテナンス性を向上させる為の機能です
実装例
例えば、controllerの場合は下記の様に利用します。
まず、controllersディレクトリ配下のconcernsに ファイルを作成します(名前は任意)
app/controllers/concerns/common.rb
module Common extend ActiveSupport::Concern def create_url(post) view_context.link_to post.title, post end end
これでメソッドの定義は完了です。 後は、このメソッドを利用したいコントローラーに 「include」という呼び出す為のコードを記述すれば設定完了です。
app/controllers/posts_controller.rb
class PostsController < ApplicationController include Common def create create_url(post) end
ビューヘルパーをコントローラーで呼び出す「view_context」
【結論】
・link_toなどのビューでのみ用いる事が可能な
ヘルパーメソッドは、view_contextで
コントローラーに呼び出す事が可能
・ヘルパーメソッドをコントローラーに呼び出せると、
ヘルパーメソッドで生成されたHTMLを
そのままDBに保存するなど事が可能になる
【目次】
【本題】
コントローラーにビューヘルパーを呼び出したい
業務でビューヘルパーの「link_to」を、
コントローラーに呼び出したいという場面があったので、
今回はそれをまとめます。
必要になった場面
仕事のコードをそのまま載せる事はできないので、
必要になった場面を、例え話を交えてお伝えします。
例えばブログ投稿サイトで、投稿に「いいね」をすると
下記の様にユーザーに通知が飛ぶ様な機能があるとします。
「○○」さんが、あなたの投稿した「△△」に、いいねをしました
「〇〇」はユーザー名で、
「△△」は自身が投稿した内容のタイトルが表示されます。
この「」内が、それぞれのリンクになっていて、
「〇〇」はユーザーのプロフィール画面へ、
「△△」は投稿した内容の詳細ページへ、
飛ぶ様なコードを書きたいというのが、今回実装したい機能です。
ビューだけでHTMLの生成は困難
ビューでlink_toを用いてリンクを生成しようとすると、
下記の様なコードになると思います。
<div> 「<%= link_to @user.name, @user %>」さんが、 あなたの投稿した「<%= link_to @post.name, @post %>」に、 いいねをしました </div>
但し、通知は「いいね以外」の種類もありますので、
そレラ全てに上記の様なコードを用意すると、非常に冗長になります。
なので、通知内容を下記の形式で直接データベースに保存し、
そのままビューに呼び出しても、リンクが反映される方法を採用しました。
"「<a href="/user/1">ホゲホゲ</a>」さんが、 あなたの投稿した「<a href="/post/1">フガフガ</a>」に、いいねをしました"
その為に今回用いたのが、「view_context」です。
「view_context」について
「view_context」はビュークラスのインスタンスで、
コントローラー上でビューヘルパーを呼び出す為に用いられます。
基本的な記述例は下記の通りです。
view_context.helper
実装例
では先ほどの話に戻って、実装例を紹介します。
まずnotificationsというテーブルを作成して、
通知すべき内容が発生したら、下記の様なレコードを保存するとします。
"「<a href="/user/1">ホゲホゲ</a>」さんが、 あなたの投稿した「<a href="/post/1">フガフガ</a>」に、いいねをしました"
まずはリンクを生成する為のメソッドを「view_context」を用いて定義します。
def create_url(instance) view_context.link_to instance.title, instance end
次にそのメソッドを用いて、userとpostのリンクを生成します。
user_url = create_url(@user) post_url = create_url(@post)
あとは、それをnotificationsテーブルに保存します
Notification.create!(messege: t('common.comment_create', user_name: user_url, post_name: post_url))
なお、上記のコードは、
下記の辞書ファイルで定義した文言で保存する様にしています。
ja:
common:
comment_create: "「%{@user_name}」さんが、あなたの投稿した「%{@post_name}」に、いいねをしました”
こうすればビューには、下記のコードだけで
リンクを保持した文言を表示させる事が可能になります。
<%= @notification.messege %>